〔概要〕Web上のCSVデータ(あるいはExcelデータ)の整形を試すプログラムです。
気象庁の過去の気象データ・ダウンロード・サイトから宮崎県の5年間の気象データを手動でダウンロードしたものを整形します。
- 参考文献
〔技法〕pandas
〔手順〕
- 過去の気象データ・ダウンロードサイトの確認
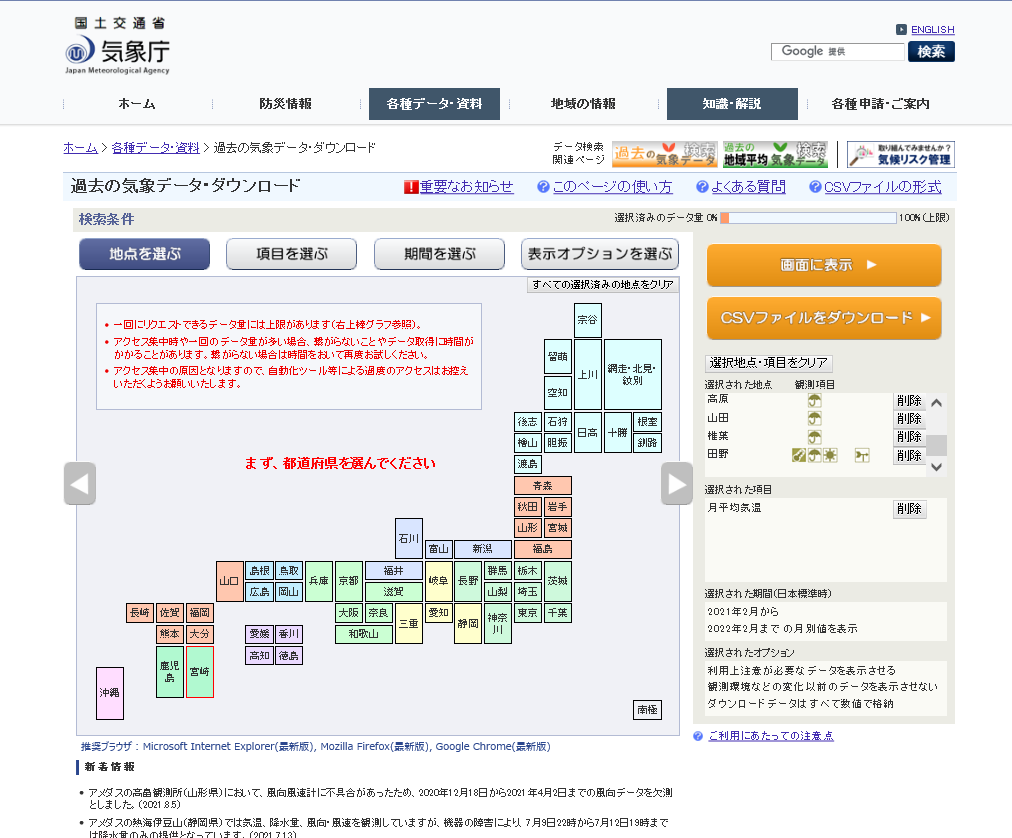
- たとえば宮崎県を選択します。
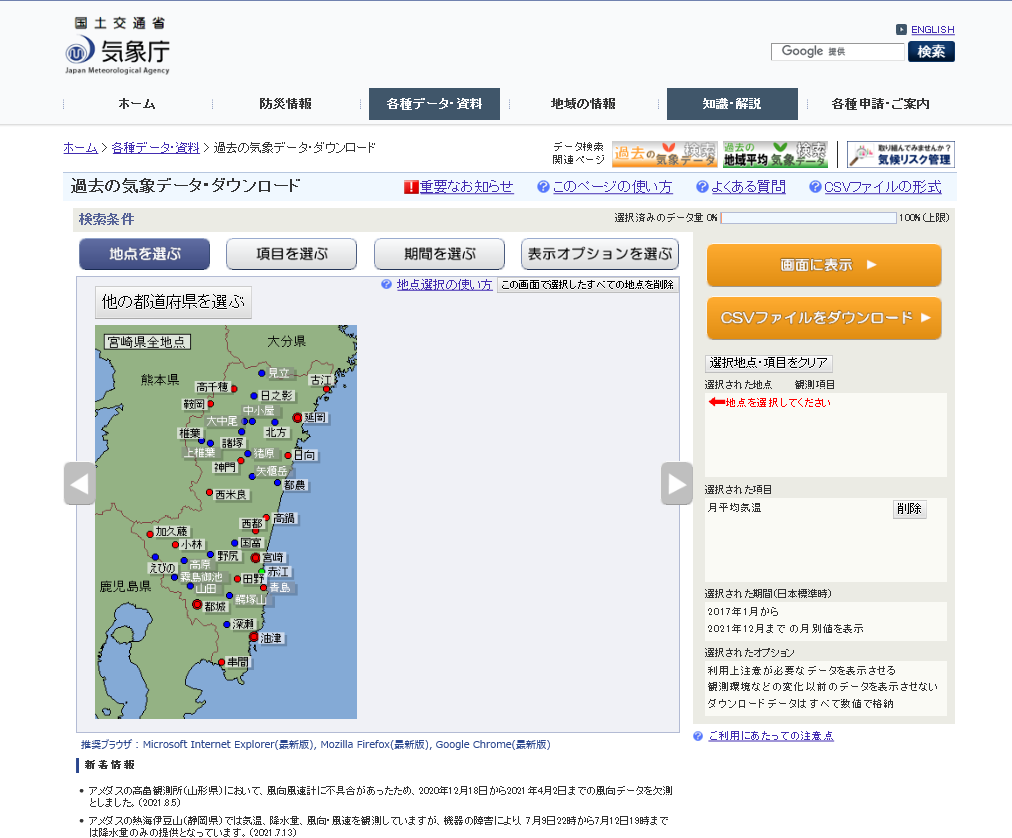
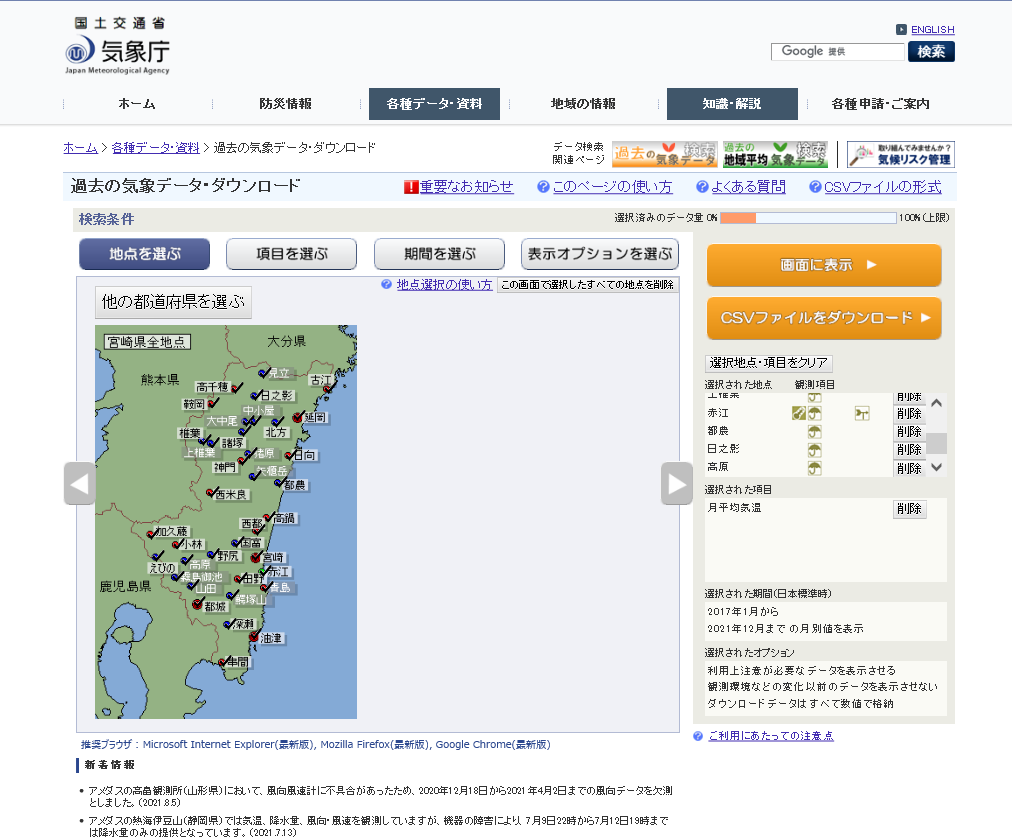
- 地図内左上の[宮崎県全地点]をクリックします。すると、全地点が選択されてチェックマークが表示されます。
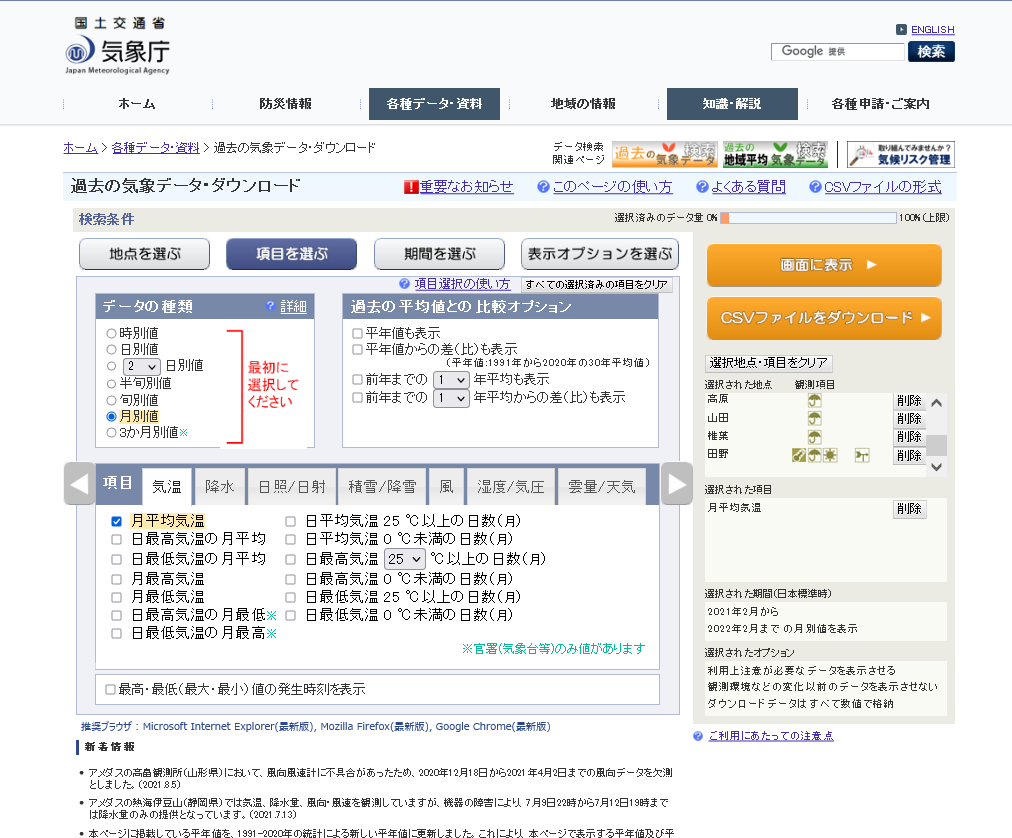
- [項目を選ぶ]を選択し設定します。
- [期間を選ぶ]を選択し設定します。
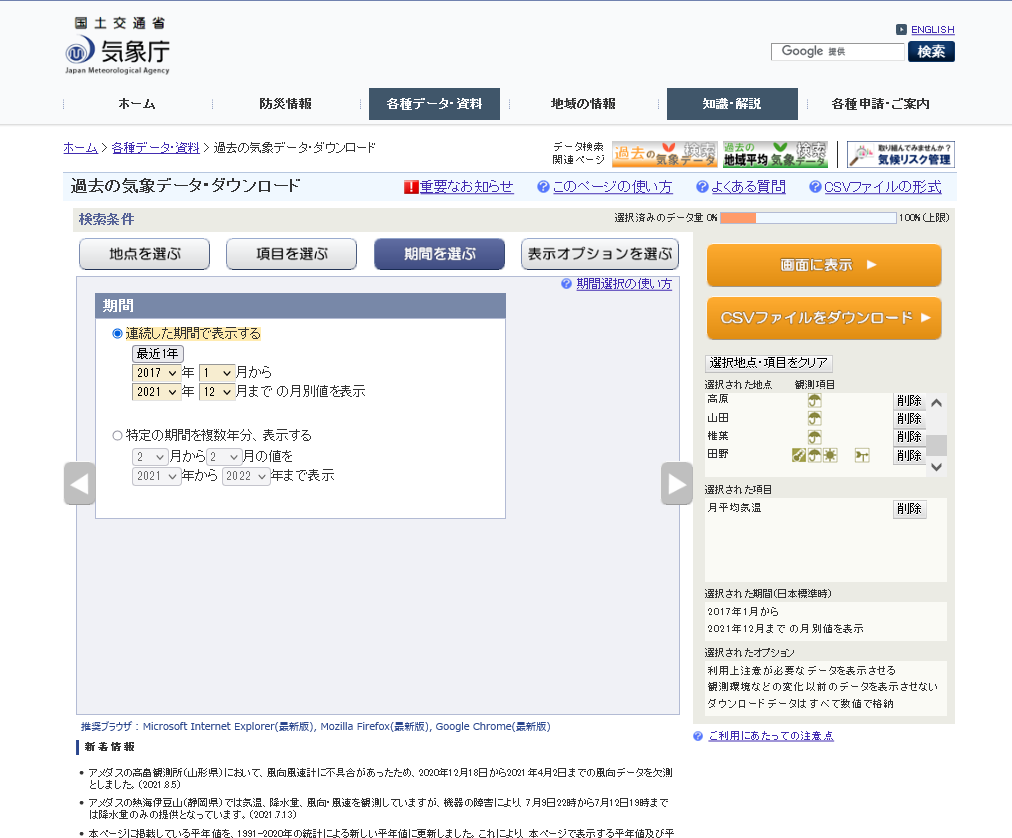
- [表示オプションを選ぶ]を選択し設定します。[観測環境などの変化前の値を表示(格納)しない。]を選択します。
- [CSVファイルをダウンロードする]ボタンをクリックしてダウンロードします。そして、ダウンロードしたファイル(この場合は、data.csv)をコピーして「data.org.csv」のような別の名前を付けて、元データとして保存しておきます。以降では、「data.csv」という名前のファイルを操作対象にします。
- ダウンロードしたCSVファイルをExcelで確認します。
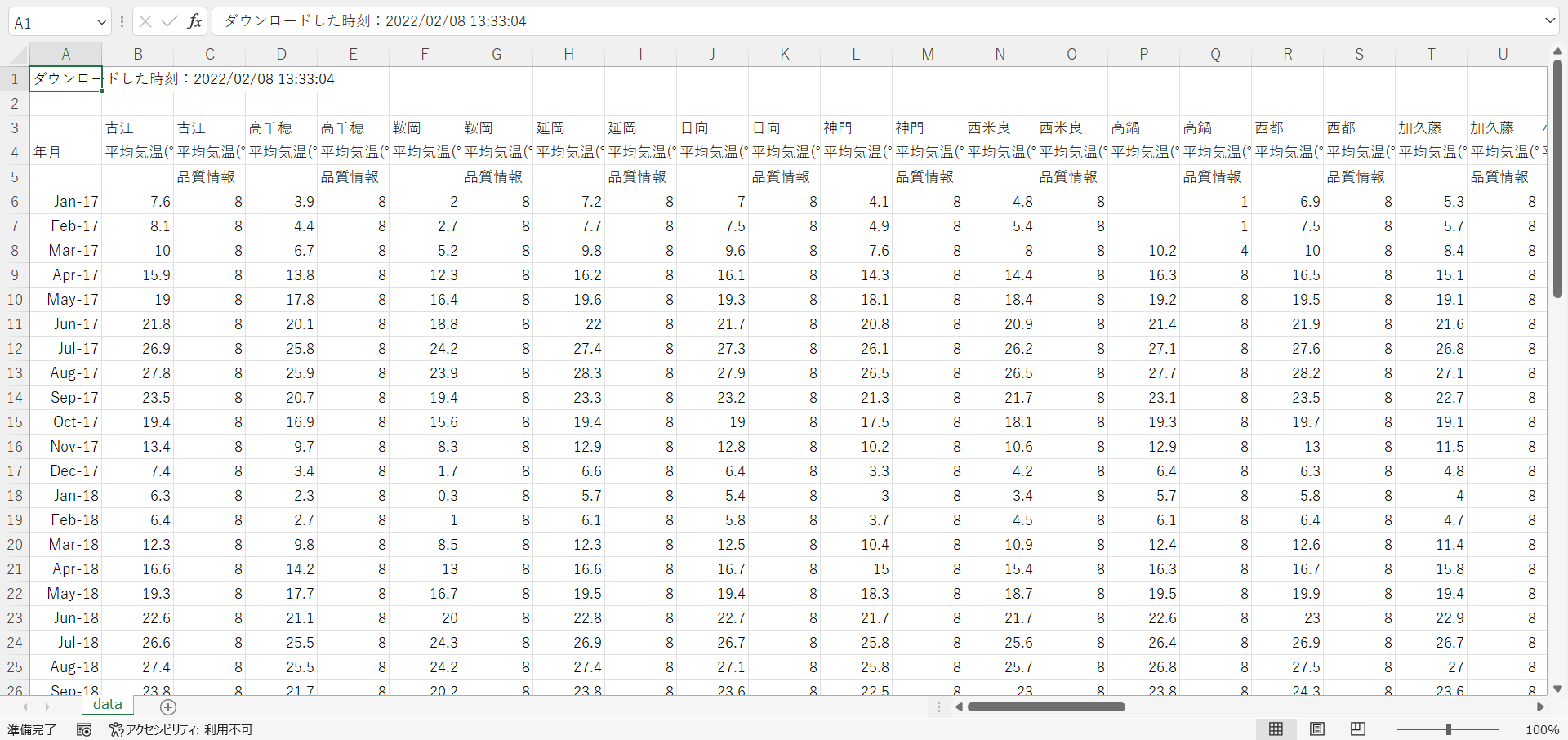
- データの処理においては、まずデータの内容や特徴の全体像を把握することが重要です。そして、以降の処理に適した形に整形しておきます。このことを前処理と呼びます。前処理は、表形式のデータであればExcelを使うと簡単にできる場合もあればプログラム(Pythonなど)の方が楽な場合もあります。
- 今回は観測地点ごとの5年間程度の平均気温を求めたいとします。そうすると、1~2行目、4~5行目は不要です。なお、「高鍋」の最初の部分に欠損があるので、2017年分の行全体を削除することにします。また、A列も不要なので削除します。これらの操作はExcel上で手作業で行います。なお、3行目の観測地点名は最終的には不要になるかもしれませんがとりあえず残しておくことにします。
- 変更したデータをファイル名「data.csv」として保存します。
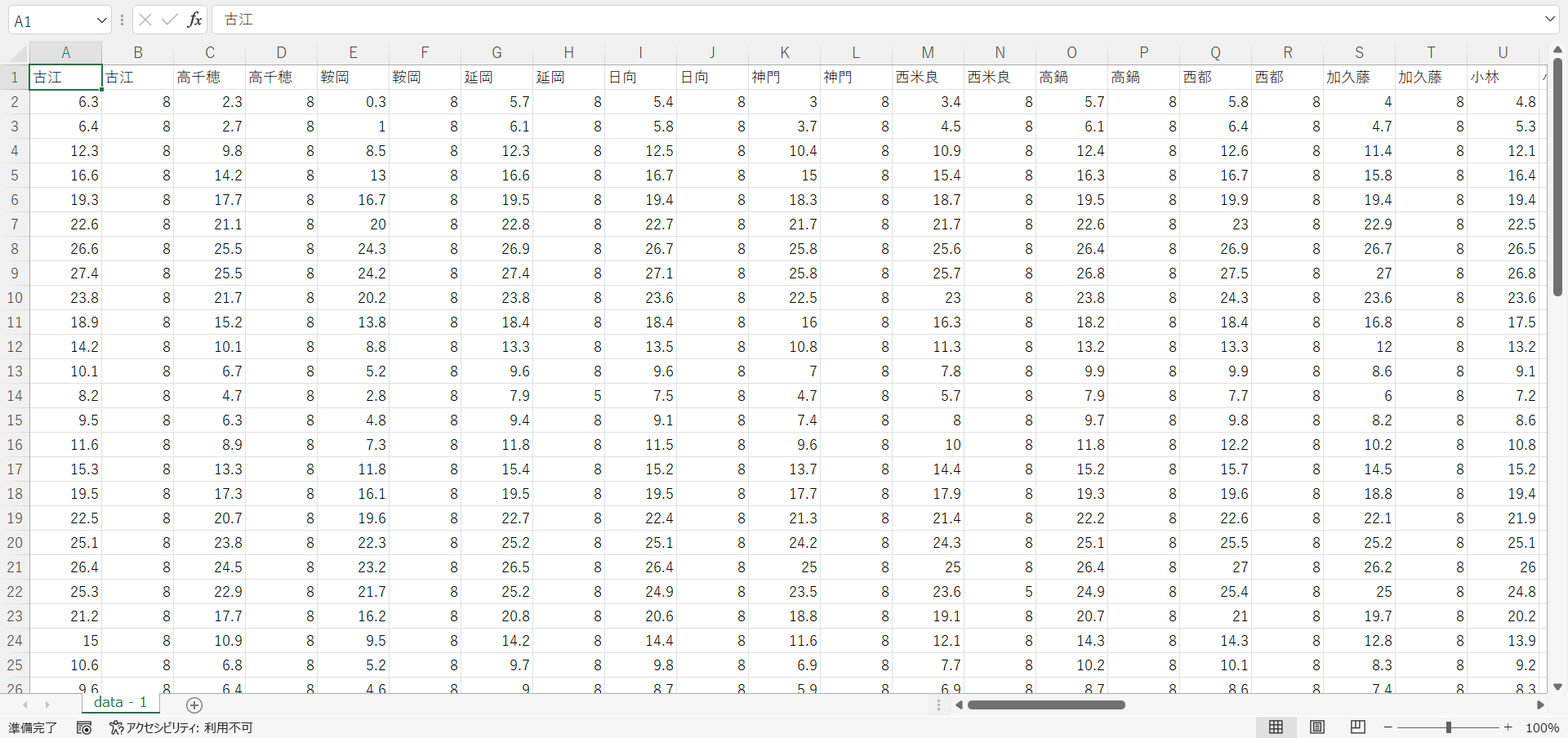
- そうすると、気温が格納されている列は1,3,5…のような奇数列ですので、偶数列は削除する、つまり奇数列のみ取り出すことになります。この作業もExcelで手動で行ってもよいのですが、もし列数が多いと大変になるので、ここでプログラムの力を借りることにします。そのために、文末のプログラムを実行します。このプログラムを実行すると、ファイル名「data_extract.csv」が出力されます。
- 出力されたファイル「data_extract.csv」をExcelで開きます。内容を確認します。そして、このデータ内の青島などデータの存在しない列を手動で削除します。
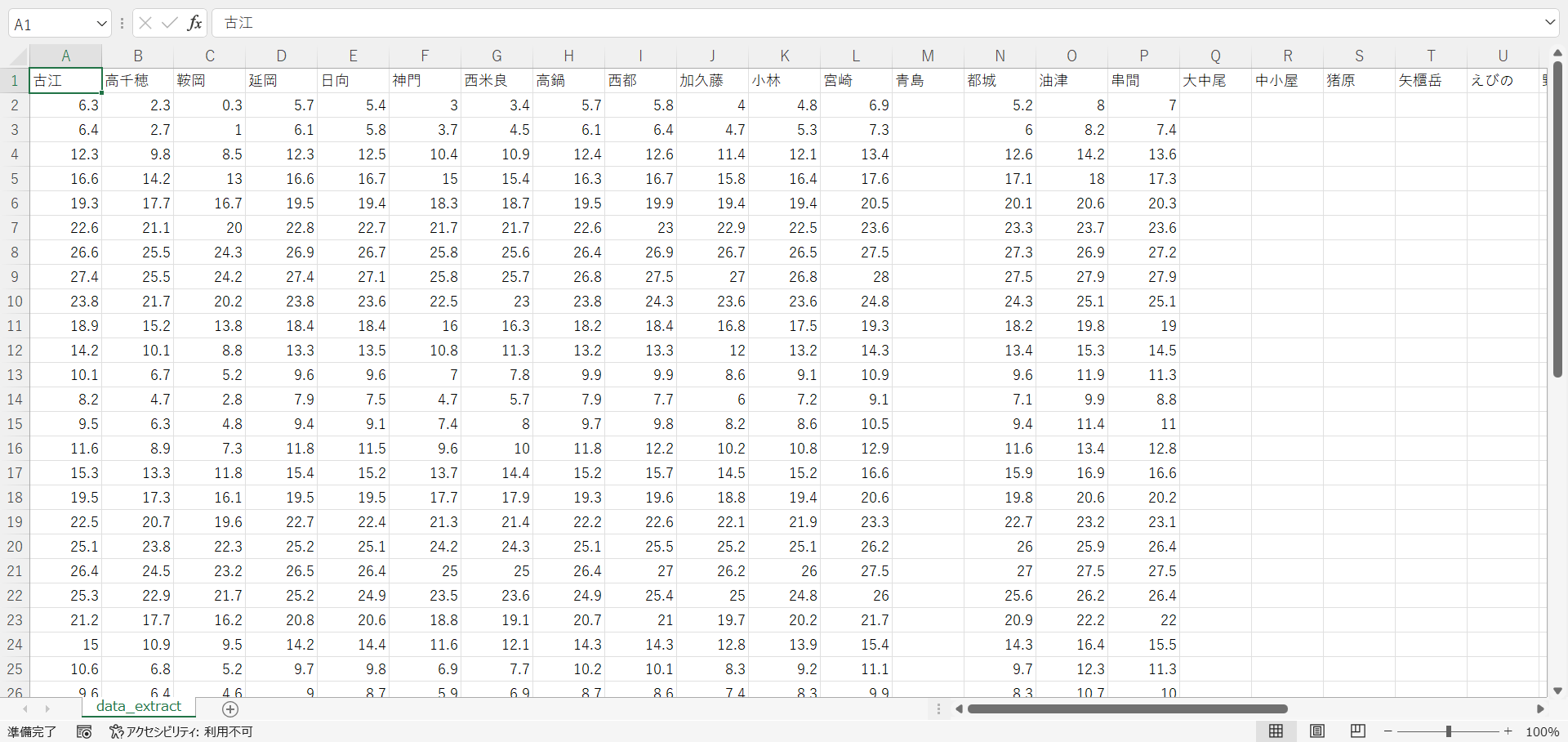
- 各観測地点の平均をExcelのAverage関数で求めます。
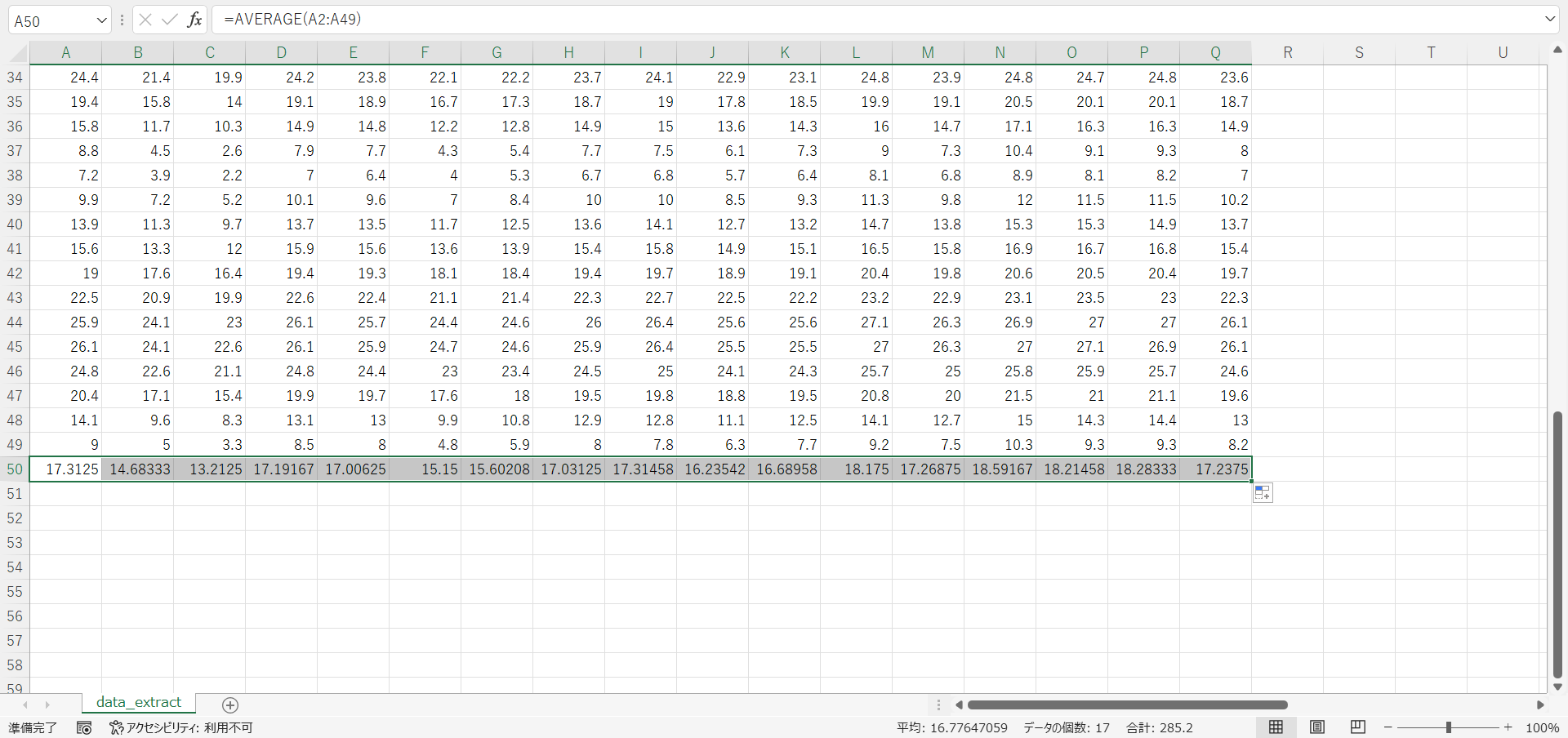
- 平均値の行をコピーして値として貼り付けます。
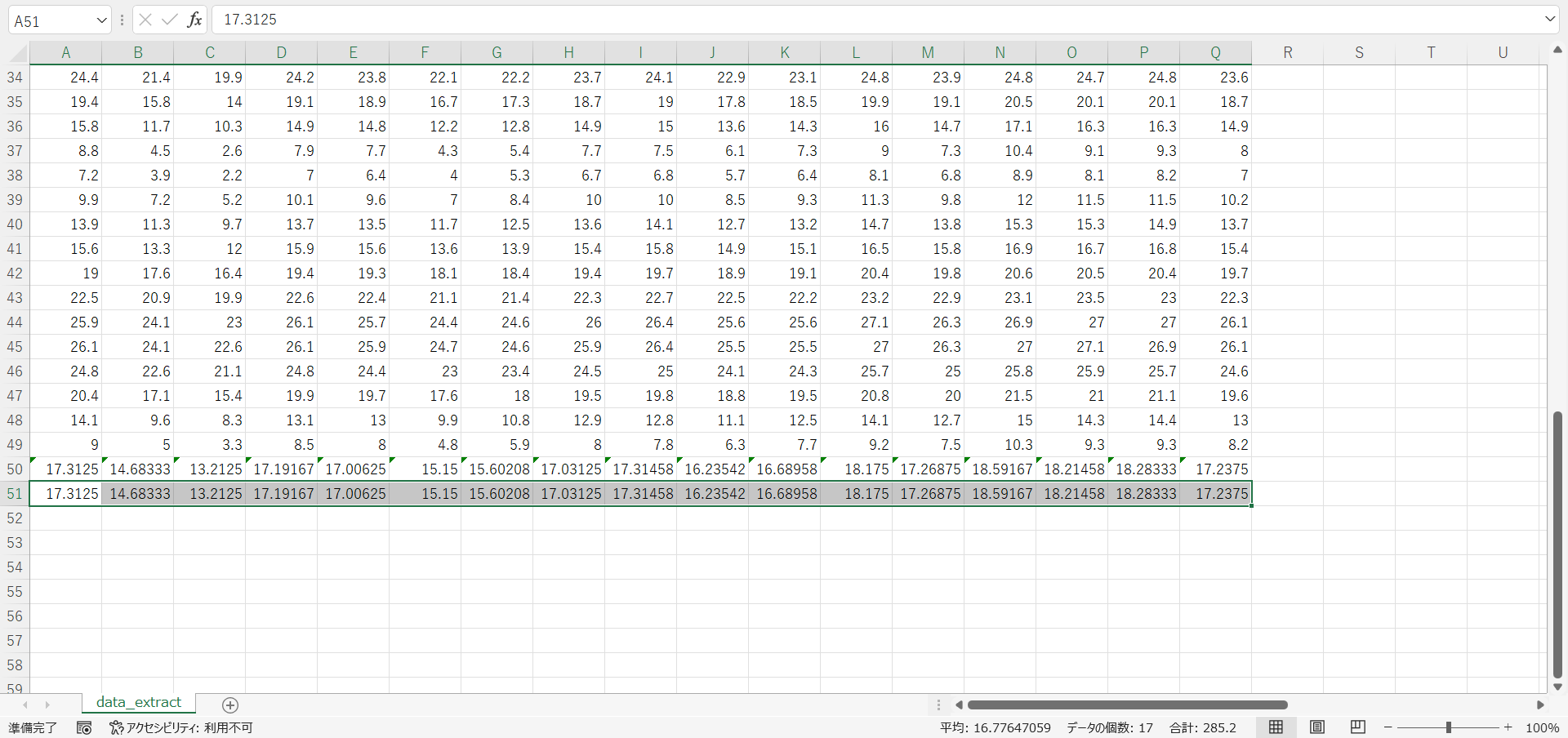
- 観測地点名と貼り付けた平均値とを除いた行をすべて削除します。
- ファイル「data_extract.csv」の内容をテキストエディタ(メモ帳やサクラエディタなど)で確認します。
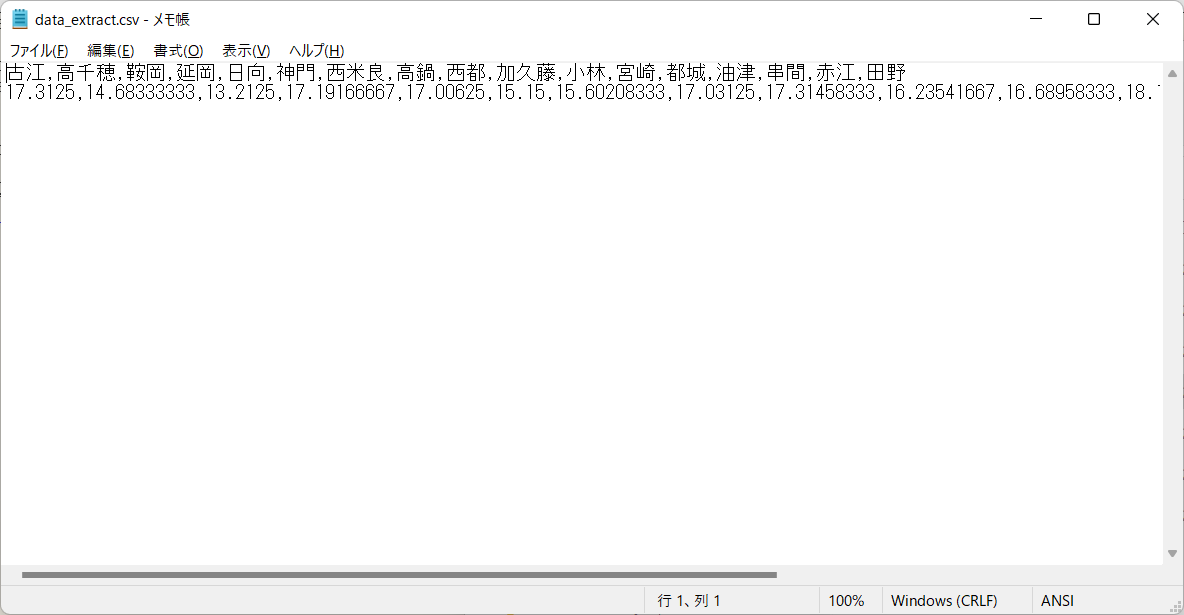
- ファイル「data_extract.csv」の文字コードは「shift_jis」形式であるため、Pythonのデフォルトである「UTF-8」形式で保存しておきます。なお、UTF-8形式であることがすぐにわかるように、ここでは「data_extract.utf8.csv」という名前を付けてみました。
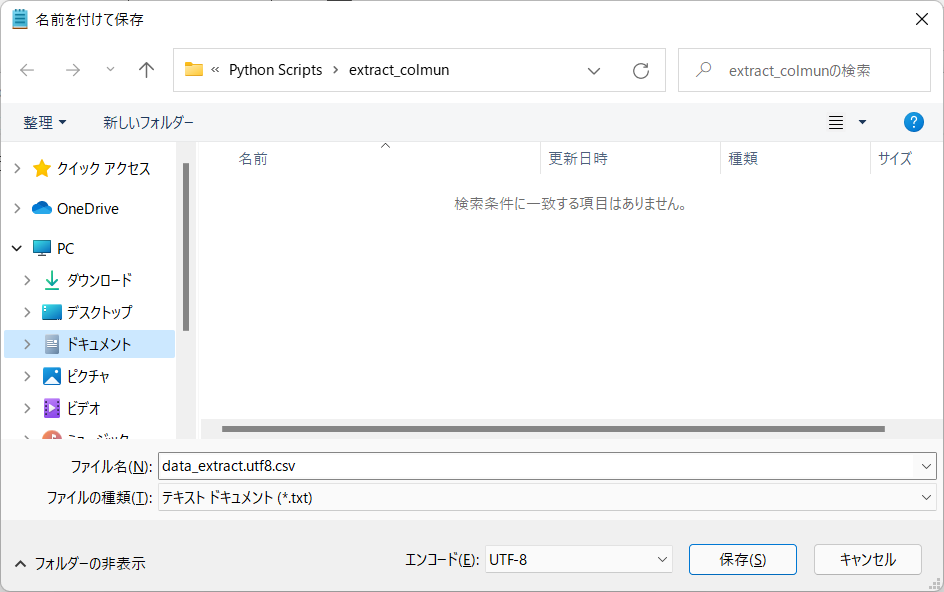
- 以上で、観測地点ごとの4年間(当初の予定は5年間)の平均気温を求めたCSV形式のファイルが作成できました。
〔プログラム〕
import pandas as pd
df = pd.read_csv('data.csv', encoding='shift_jis')
print(df)
# 列数を確認する場合
# print(len(df.columns))
df.iloc[:, 0::2].to_csv("data_extract.csv", encoding='shift_jis', index=False)
Copyright (C) 2022 Easy Programming